Textanalyse mit MAXQDA: Schritt-für-Schritt-Anleitung
Sie sind mit einer überwältigenden Menge an Daten konfrontiert? Die Textanalyse schafft Abhilfe.
Eine Qualitative Datenanalyse mag auf den ersten Blick sehr überwältigend wirken: ein Haufen Feldnotizen, stundenlange Interviews mit vielen verschiedenen Personen und Hunderte von Bildern oder Dokumenten, die analysiert werden müssen. Wie schaffen es Forschende eine so große Datenmenge zu analysieren und ihre Ergebnisse in zwei bis drei Stichpunkten pro Forschungsfrage zusammenzufassen? Eine Möglichkeit dies zu erreichen ist die Methode der Textanalyse. Die Textanalyse bietet einen systematischen Ansatz zur Identifizierung, Organisation und Erschließung von Bedeutungsmustern, beziehungsweise, von Themen in qualitativen Daten (Braun & Clarke, 2012). In diesem Blogbeitrag lernen Sie die einzelnen Schritte der Textanalyse kennen und wie Sie MAXQDA dafür nutzen können.
Die Textanalyse hat sich in den letzten Jahren zu einer der am häufigsten verwendeten analytischen Ansätze in den Sozialwissenschaften entwickelt. Braun et al. (2019) weisen darauf hin, dass die Textanalyse und die Inhaltsanalyse eine gemeinsame Geschichte haben und seit den 1980er Jahren in gesundheits- und sozialwissenschaftlichen Studien für die qualitative Datenanalyse verwendet werden. Eine schnelle Suche auf Google Scholar des Begriffs „Textanalyse“ (in Anführungszeichen) führt zu mehr als 370.000 Ergebnisse. Allein der Schlüsselartikel „Using Thematic Analysis in Psychology“ von Braun und Clarke (2006) wurde bis Mai 2022 mehr als 126.000 Mal zitiert. Diese Daten zeigen die Beliebtheit der Textanalyse. Die Beliebtheit der Textanalyse mag mit der Modularität und Flexibilität zusammenhängen, die sie Forschenden bei der Analyse qualitativer Daten bietet. Allerdings ist die Textanalyse auch ein sehr systematischer Prozess, der rekursiv ablaufen muss. Zusätzlich erfordert die Textanalyse, dass Forschende sich intensiv mit ihren Daten auseinandersetzen. Um Textanalysen zu systematisieren, haben Braun und Clarke (2006, 2012) ein sechsstufiges Verfahren vorgeschlagen, das qualitative Forschenden anleiten soll.
Das Forschungsprojekt
In diesem Blog-Beitrag werde ich eine kürzlich erschienene Publikation von mir als Beispiel dafür vorstellen, wie ich MAXQDA eingesetzt habe, um den sechsstufigen Ansatz der Thematischen Analyse weiterzuentwickeln. In dieser qualitativen Studie habe ich die Erfahrungen von Englisch-als-Fremdsprache-Lehrkräften (EFL) bei der Online-Fortbildung im Rahmen eines Massive Open Online Course (MOOC) zum Online-Sprachunterricht untersucht. Die Studie trägt den Titel “How massive open online courses constitute digital learning spaces for EFL teachers: A netnographic case study”: Wie der Titel schon verrät, habe ich ethnografische Methoden angewendet, um die Online-Erfahrungen von zwei EFL-Lehrenden als qualitative Fälle zu untersuchen. Eine vergleichende Fallstudie mit zwei Fällen könnte den Eindruck erwecken, dass es nicht so viele Daten zum analysieren gibt, aber das Gegenteil ist der Fall. Ein typisches Merkmal ethnografischer Studien ist, dass der oder die Forschende über einen längeren Zeitraum in die untersuchte Kultur eintauchen muss.
Die Forschungsdaten
Hinzu kommt, dass die multimodale Natur qualitativer Daten den Forschenden ein breites Spektrum an Möglichkeiten zur Datenerhebung bietet; dementsprechend habe ich mich auf digitale Lerntagebücher (die die Reflexionen der Teilnehmenden während der gesamten Online-Lernerfahrung enthalten), halbstrukturierte Interviews und Screenshots, die die Online-Forenbeiträge der Teilnehmer und ähnliche Beiträge im Online-Kurs illustrieren, gestützt.
In der Absicht, die Erfahrungen der Teilnehmer auf erklärende Weise zu untersuchen, ohne einen rekonzeptualisierten theoretischen oder konzeptionellen Rahmen im Kopf zu haben, verwendete ich induktive Kodierung und Textanalyse. Während dieses vorläufigen Prozesses wurden die einzelnen Phasen der Textanalyse durch verschiedene Tools von MAXQDA unterstützt.
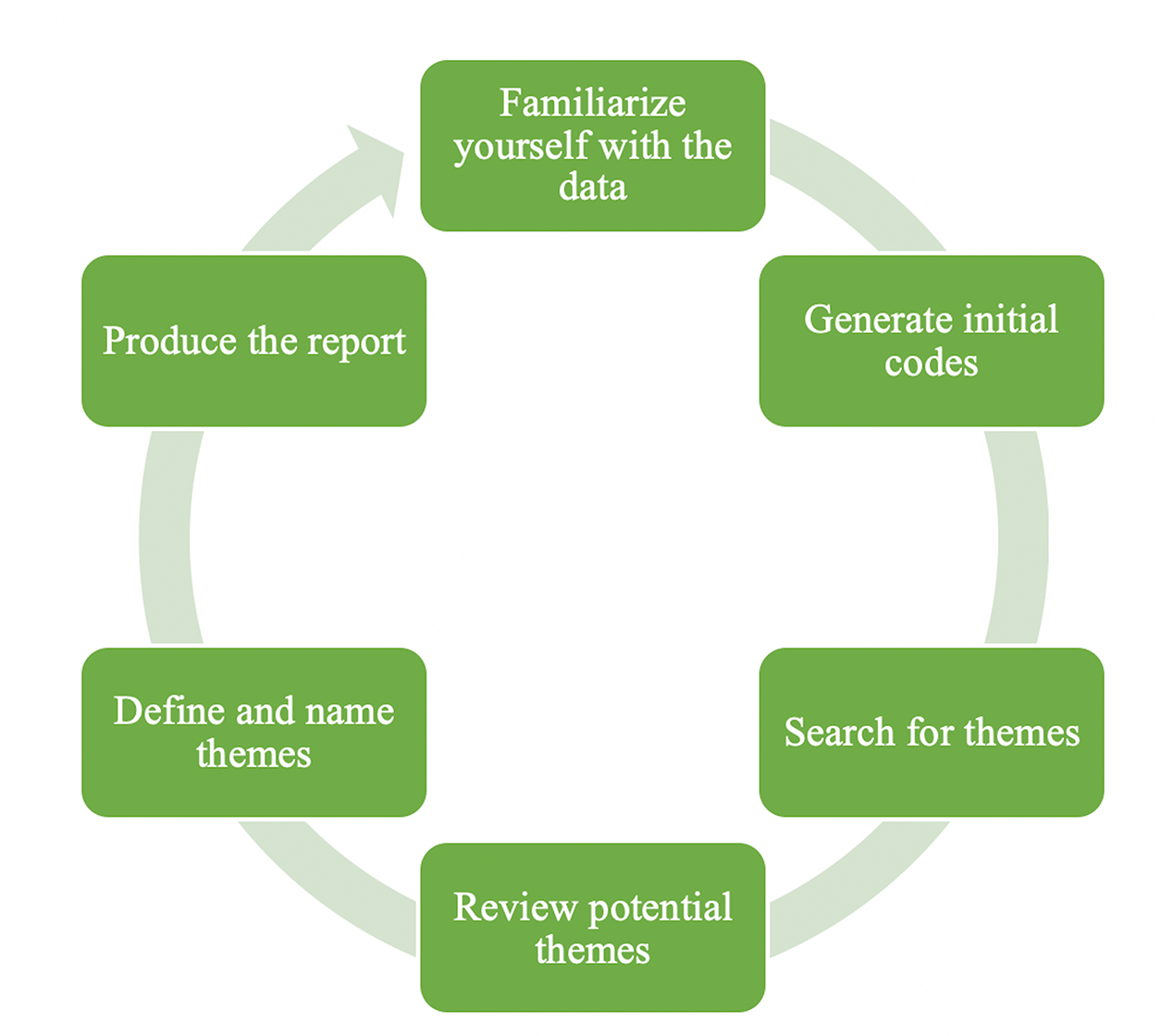
Die sechs Phasen der Textanalyse
Abbildung 1: Textanalyse-Prozess in sechs Phasen (nach Braun & Clarke, 2006, 2012)
Phase 1: Machen Sie sich mit den Daten vertraut
Ähnlich wie bei anderen Ansätzen der qualitativen Datenanalyse müssen Forschende, die ihre Daten thematisch analysieren, zunächst umfassend in ihre Daten eintauchen. Wie in Abbildung eins dargestellt, beginnt der Sechs-Phasen-Prozess mit dieser Phase. Braun und Clarke (2006, 2012) betonen, dass es in dieser Phase notwendig ist, eine Fülle von Notizen und Memos aufzuschreiben, Transkripte zu annotieren, Dokumente zu unterstreichen, hervorzuheben und zu gruppieren. Dementsprechend musste ich bei meiner Untersuchung der MOOC-Erfahrungen von EFL-Lehrkräften die Audiotagebucheinträge und Interviewtranskripte der Teilnehmenden wiederholt anhören, und die Interaktionen und Beiträge der Teilnehmenden auf der Plattform wiederholt begutachten.
Über die „oberflächliche Bedeutung von Worten auf der Seite“ hinausgehen
Nach Braun und Clarke (2006, 2012) gibt es Fragen, die man im Hinterkopf behalten sollte, während man sich mit dem Datensatz vertraut macht: Wie verstehen meine Fallteilnehmenden ihre MOOC-Erfahrungen? Welche Annahmen und Überlegungen stellen sie an, wenn sie ihre Erfahrungen interpretieren? Was offenbart ihre Interpretation? Obwohl es sich hierbei um die erste Phase der Textanalyse handelt, ist dies für alle qualitativen Forschenden eine ziemlich überwältigende Aufgabe; diese Phase ist jedoch von entscheidender Bedeutung, weil wir damit beginnen können „unsere Daten als Daten zu lesen“, was bedeutet, dass wir über „die oberflächliche Bedeutung von Worten auf der Seite“ hinausgehen (Braun & Clarke, 2012, S. 60, Hervorhebung im Original).
Gruppierung der Daten
MAXQDA war für mich besonders hilfreich, um mich mit den Daten vertraut zu machen, da es mir erlaubte, mit der Gruppierung meiner verschiedenen Datenquellen zu experimentieren, sich mit verschiedenen Arten von Daten zu beschäftigen und Audiodateien einfach zu transkribieren.
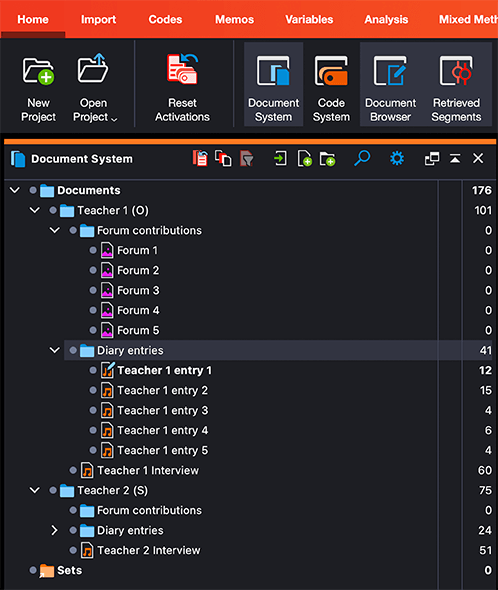
Abbildung 2: Das Dokumentensystem meines Forschungsprojekts mit MAXQDA 2022
Das Dokumentensystem von MAXQDA ermöglichte es mir, mit der Gruppierung meiner Daten auf verschiedene Weise zu experimentieren. Da es sich bei meiner Studie um eine vergleichende Fallstudie handelt, die über die Erfahrungen von zwei Fallteilnehmenden (Lehrerin 1 und Lehrerin 2, siehe Abbildung 2) berichtet, habe ich mich entschieden, die Daten nach Teilnehmenden zu gruppieren.
Transkribieren der Daten
Außerdem habe ich verschiedene Datentypen wie Audiodateien und Bilder hochgeladen. Da ich Audiotagebücher von zwei verschiedenen Quellen gesammelt habe, die unterschiedliche Geräte zur Aufzeichnung ihrer Tagebucheinträge verwendet haben, musste ich mit zwei verschiedenen Datenformaten umgehen. Mit MAXQDA war ich in der Lage, Audiodateien in diesen beiden Datenformaten ohne Schwierigkeiten hochzuladen und abzuspielen. Außerdem konnte ich die Audiodateien mit MAXQDA transkribieren. Da ich beim Transkribieren Zeitmarken angelegt habe, konnte ich zu ausgewählten Stellen der Audiodatei zurückgehen und erneut anhören, was mir bei der Einarbeitung in den Datensatz sehr geholfen hat.
Phase 2: Generierung erster Codes
Codierung in der Thematischen Analyse
Sobald das Dokumentensystem eine gewisse Form angenommen hat, beginnt die qualitative Codierung. Nach Braun und Clarke (2012) sind Codes „die Bausteine der Analyse“ (S. 61) und helfen Forschenden, ihre Daten vor dem Hintergrund ihrer vorläufigen Forschungsfragen zu verstehen. Nach Kuckartz und Rädiker (2019) weisen Forschende einem Segment ihrer Daten einen Code zu. Dies kann auf zwei generische Arten geschehen, dem theoriegeleiteten, deduktiven Ansatz und dem Daten-geleiteten, induktiven Ansatz. Bei der Textanalyse kann die Codierung auf beide Arten erfolgen, und die jeweiligen codierten Segmente können gemeinsam auftreten und sogar miteinander verbunden sein.
Auf der Suche nach neuen Codes
Nachdem ich mich mit meinen Daten vertraut gemacht habe, habe ich mit der Erstellung erster Codes begonnen. Da ich mich nicht auf einen vorgefertigten theoretischen Rahmen bezogen habe, der meinen analytischen Blick besonders prägt, habe ich mich für daten-basiertes, induktives Codieren entschieden und nach potenziellen Codes und Code-Gruppen in meinem Material Ausschau gehalten. Als ich angefangen habe Codes zu generieren habe ich zwei Funktionen von MAXQDA ausgiebig benutzt: offenes Codieren und Memos. Das offene Kodieren mit MAXQDA ist sehr intuitiv, und die Memos haben mir geholfen, meine Ideen und Überlegungen zurückzuverfolgen, zum Beispiel wenn ich einen neuen Code erstellt habe, der auch vorherige Textstellen betraf. Mithilfe der Memos konnte ich entscheiden, ob ich einen bereits erstellten Code auch für diese Textstelle verwenden kann.
Phase 3: Suche nach Themen
Ausschau halten nach auftauchenden Themen
Nachdem ich das Gefühl hatte, dass alle Datenquellen der Textanalyse ausreichend codiert bzw. neu-codiert wurden, ging ich von den Codes zu den Themen über. Nach Braun und Clarke (2006) sind Themen „gemusterte Antworten oder Bedeutungen innerhalb des Datensatzes“, die in irgendeiner Weise mit den Forschungsfragen zusammenhängen (S. 82). Die Suche nach Themen ist ein sehr aktiver Prozess. Anders als der Name der Phase vermuten lässt, sucht der oder die Forschende jedoch nicht nach Themen, sondern konstruiert Themen aktiv. Braun und Clarke (2012) vergleichen Forschende in dieser Phase mit Bildhauer:innen, die aktiv Entscheidungen treffen, welche das Endergebnis tiefgreifend beeinflussen, anstatt mit Archäolog:innen, die nach Fossilien (d. h. Themen) graben, die in den Daten eingebettet sind, unabhängig von dem Schmutz, der um sie herum entfernt werden muss. Diese Auffassung kam mir als qualitativer Datenanalytiker sehr entgegen, da mein gesamter analytischer Ansatz Daten-basiert war und meine Forschungsfragen eher auf das Verstehen als auf das Erforschen abzielten. Gleichzeitig musste ich ein aktiver Sinnstifter und kein passiver Beobachter sein; ich musste mit meinen Daten kommunizieren und ihnen einen Sinn geben, während ich Themen konstruierte.
Muster durch Visualisierungen entdecken
MAXQDA hat mir viele Möglichkeiten geboten, aktiv zu analysieren und mit meinen Daten auf einer konzeptionellen Ebene zu kommunizieren. Mir persönlich fällt es leichter, Informationen zu synthetisieren, wenn ich sie visualisiere ; folglich helfen mir Diagramme, Bilder und Visualisierungen
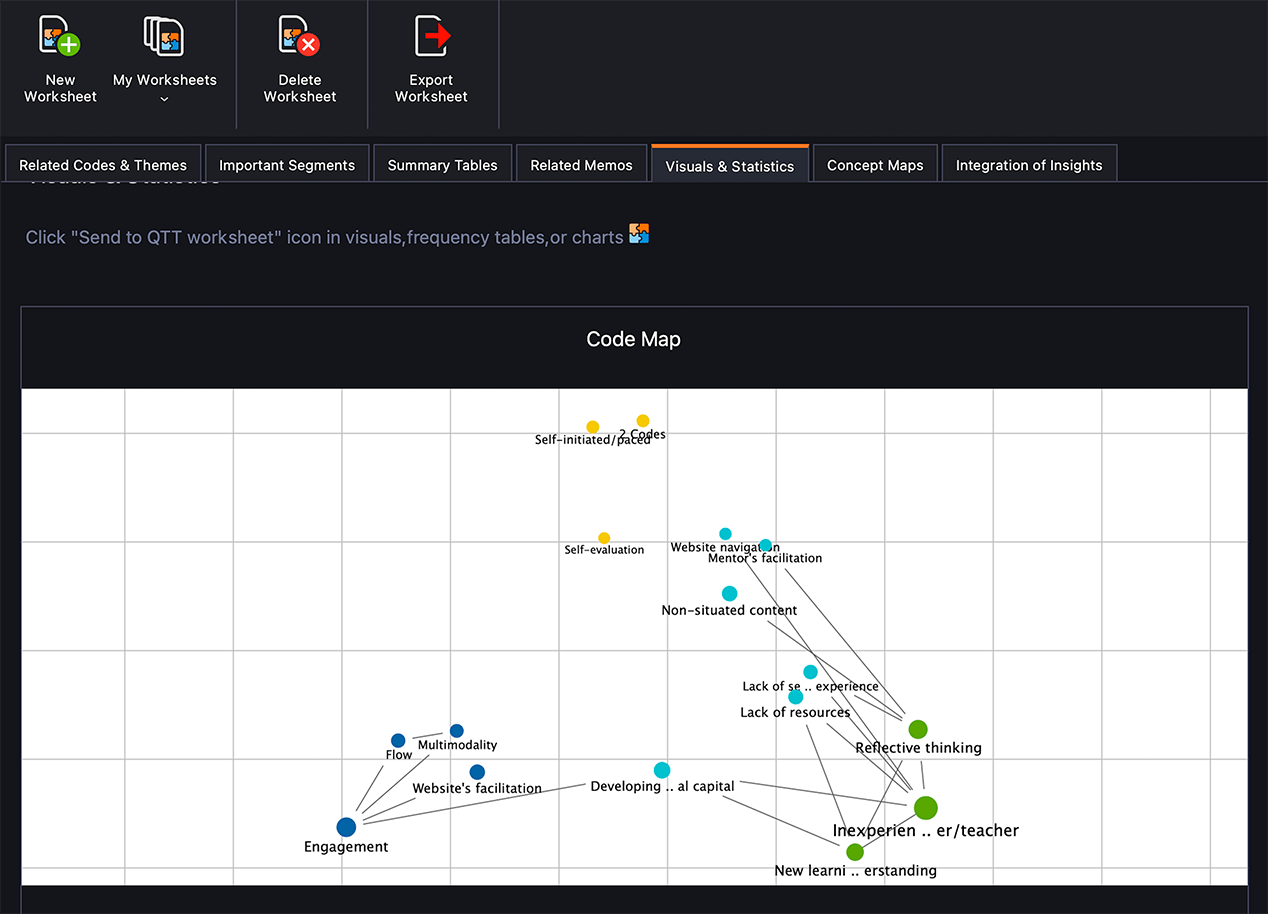
dabei, Beziehungen zwischen Codes und aufkommenden Themen sowie Dokumenten und Teilnehmern zu erkennen. In ähnlicher Weise helfen mir summative Workflows und Pipelines, mich in dem langen Prozess zurechtzufinden, der für die meisten qualitativen Analyseansätze, einschließlich der Textanalyse, erforderlich ist. Dabei habe ich insbesondere von drei MAXQDA Funktionen sehr profitiert: Code Maps, MAXMaps und Questions, Themes & Theories (QTT).
Eine ganzheitliche Sichtweise gewinnen
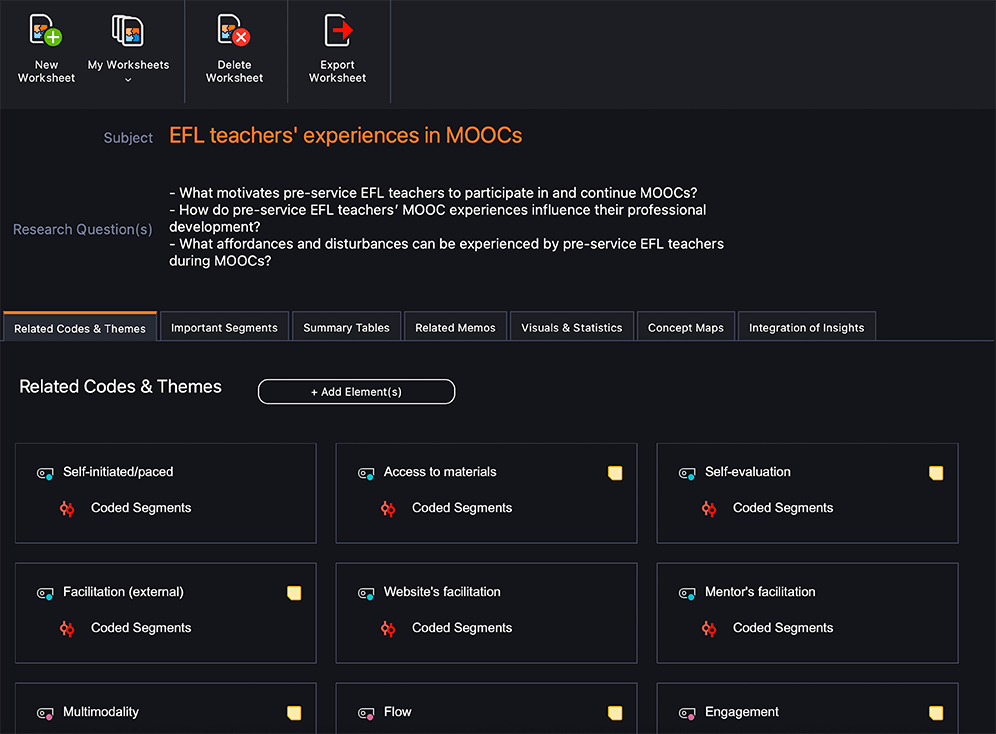
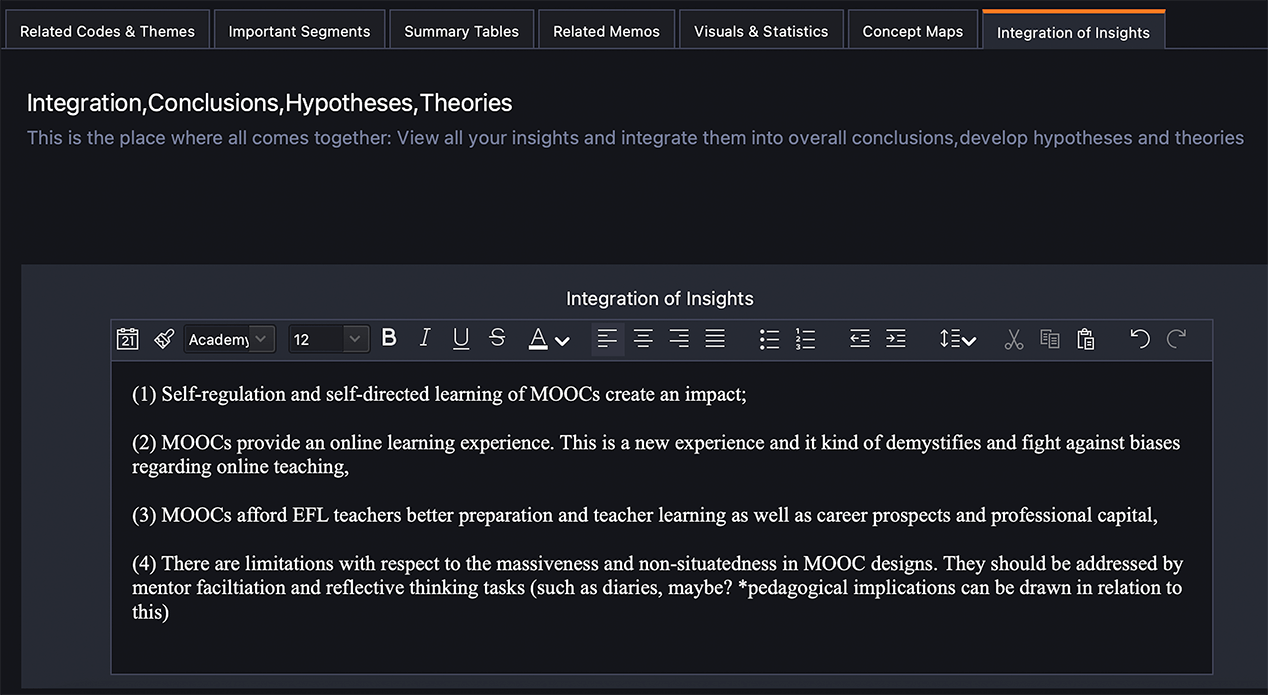
Abbildung 3: Screenshots aus meinem QTT-Arbeitsblatt
In Abbildung 3 sind zwei Screenshots von meinem QTT-Arbeitsblatt abgebildet, das ich bei meiner Datenanalyse verwendet habe.
MAXQDA ermöglicht die Erstellung von Code Maps, die die Beziehungen zwischen Codes darstellen: Codes die häufig zusammen, oder in einem gewissen Abstand voneinander auftauchen, sind näher beieinander, als Codes, die selten zusammen auftauchen. Ich beginne meine Textanalyse immer mit Code Maps, weil sie es erlauben mit wenigen Klicks eine Meta-Position einzunehmen – nach dem langen und sich wiederholenden Prozess des Eintauchens und Codierens. Code Maps erlauben es einen Schritt zurückzutreten und einen ganzheitlicheren Blick auf die Codes und ihre Beziehungen zueinander zu erhalten. Wie bereits erwähnt sind Code Maps nur eine der zahlreichen Funktionen von MAXQDA, die in dieser Phase genutzt werden können. Außerdem sollte nicht nur eine Funktion genutzt werden, denn die Textanalyse erfordert, dass die Forschenden den Prozess der Bedeutungserstellung aktiv mitbestimmen.
Questions-Themes-Theories für die Textanalyse nutzen
Dies bringt mich zu einem weiteren sehr wichtigen Visualisierungstool von MAXQDA: MAXMaps. MAXMaps – MAXQDA’s Tool für Concept Maps und ähnliches – bot mir einen Raum für ein angeregtes Brainstorming über meine Codes und ersten Themen. Mit MAXMaps können Codes und Dokumente als Icons dargestellt werden, Beziehungen zwischen den Elementen mit Links und Pfeilen dargestellt und gekennzeichnet werden, oder Code-Modelle erstellt werden. Schließlich habe ich MAXQDA 2022 genutzt um ein Question-Themes-Theories Arbeitsblatt zu erstellen, das sowohl meine Forschungsfragen und Notizen, als auch dazugehöriges Material enthält. In das Arbeitsblatt habe ich verwandte Codes und Themen, codierte Segmente und das gesamte von mir erstellte Bildmaterial importiert. Dieses QTT-Arbeitsblatt erlaubte es mir immer wieder zu meinen Forschungsfragen und Notizen zurückzukehren, wenn ich mich bemühte, von meinen Fragen zu Themen und später zu Theorien zu gelangen.
Phase 4: Potenzielle Themen überprüfen
In dieser Phase werden die in der vorangegangenen Phase konstruierten Themen überprüft und mit dem gesamten Codesystem, den codierten Segmenten und den Dokumenten abgeglichen. Die Themen, Daten und Forschungsfragen müssen relevant sein und übereinstimmen. Dabei können die Forscher einige auftauchende Themen zu übergreifenden Themen kombinieren, während einige auftauchende Themen herausgegriffen und für irrelevant befunden werden könnten, obwohl sie sehr interessant erscheinen.
Leitfragen für eine Textanalyse
Ich habe einige von Braun und Clarke (2012, S. 65) vorgeschlagene Leitfragen genutzt, um potenziellen Themen zu überprüfen und mehrere aufkommende Themen zu übergreifenden Themen kombinieren. Ich habe diese Leitfragen wie folgt an meinen Forschungskontext angepasst:
Ist dies ein Thema, das ein Muster in meinen beiden Fallteilnehmern und/oder Datendokumenten darstellt?
Sagt mir dieses Thema etwas über meine Forschungsfragen und/oder die Erfahrungen von EFL-Lehrenden beim professionellen Lernen mit MOOCs?
Schließt dieses Thema viele codierte Segmente ein oder aus?
Gibt es genügend Daten, die belegen, dass es sich um ein starkes Thema handelt?
Ist dieses Thema kohärent, d. h. stammen die Daten zur Untermauerung dieses Themas aus ähnlichen Quellen (z. B. aus Tagebüchern)?
Diese Leitfragen waren für mich sehr hilfreich, aber ich musste dennoch intelligente Wege finden, um mit ihnen umzugehen.
Zentraler Themen mit MAXQDA’s Visual Tools auffinden
Mit MAXQDA konnte ich weitere Visual Tools für meine Textanalyse nutzen, die mich noch weiter gebracht haben. Zum Beispiel habe ich Code- und Dokumentmatrizen genutzt, um zu prüfen und entscheiden, ob meine anfänglich konstruierten Themen stark sind und ob ich aus ihnen relevante übergreifende Themen konstruieren kann.
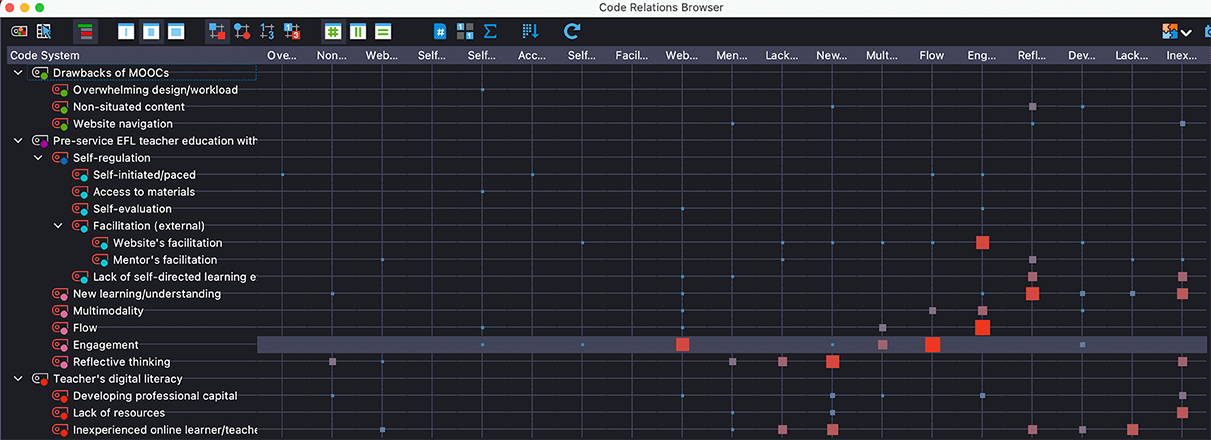
Zunächst habe ich den Code Relations Browser verwendet, um die Beziehungen zwischen den Codes besser zu verstehen. Eine Implikation, die ich zog, ist zum Beispiel die starke Beziehung zwischen dem Gefühl des Engagements meiner Teilnehmenden und der Erleichterung durch die MOOC-Plattform. Dies veranlasste mich, zu meinen codierten Segmenten zurückzukehren und zu entscheiden, ob ich aus dieser Beziehung ein Thema konstruieren kann und ob es einen anderen Code gibt, der diese Beziehung beschreibt (z. B. Flow).
Abbildung 4: Code-Relations-Browser
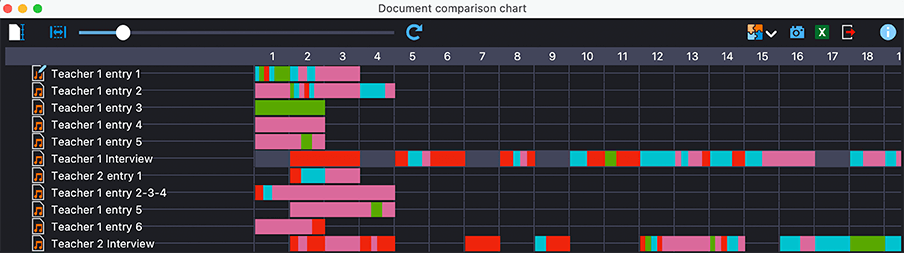
Ähnlich wie der Code Relations Browser und der Code-Matrix-Browser hat mir die Nutzung des Dokumentenvergleichsdiagramms geholfen, meine ursprünglichen Codes mit den Leitfragen von Braun und Clarke zu überprüfen. Nachdem ich den Codes in meinem Codesystem Farben zugewiesen hatte (siehe mein Codesystem im linken Teil von Abbildung 4), ist zu erkennen, dass alle Audiotagebucheinträge rosafarbene Blöcke enthalten, die darauf hinweisen, dass die Fallteilnehmnden eine Art von Lernerfahrung gemacht haben (z. B. neues Verständnis, Engagement, Reflexion, Flow oder multimodales Lernen). Auch meine Interviewdaten enthielten Überlegungen der Teilnehmenden zu ihren vorhandenen oder sich entwickelnden digitalen Kompetenzen (rote Segmente).
Abbildung 5: Dokumentvergleichsdiagramm
Phase 5: Themen definieren und benennen
Dies ist die nächste Phase der Textanalyse, die eng mit der Vorherigen zusammenhängt. In dieser Phase überprüfen Forschende die sich abzeichnenden Themen und die erstellten übergreifenden Themen. Forschende sollten darauf achten, dass sich die Themen nicht wiederholen oder überschneiden, andernfalls müssen sie möglicherweise kombiniert werden. Braun und Clarke (2012) schlagen außerdem vor, dass Forschende Themen nur dann definieren und benennen sollten, wenn sie einen eindeutigen Schwerpunkt haben und Forschungsfragen betreffen.
Den Fokus behalten mit Question-Themes-Theories
In dieser Phase hat mir QTT geholfen meine Forschungsfragen stets im Auge zu behalten (siehe Abbildung 3). Im Ergebnis habe ich vier übergreifende Themen identifiziert: (1) die Auswirkungen des MOOC auf die Selbstregulierung, (2) die Bereitstellung einer Online-Lernerfahrung, die den Online-Unterricht entmystifizierte, (3) die Vorbereitung der angehenden EFL-Lehrenden auf eine Lehrer:innenkarriere und (4) die Einschränkungen aufgrund der hohem Nutzer:innenzahl und der Nicht-Situiertheit von MOOC-Designs.
Themen durch Codes definieren
Das Code System von MAXQDA unterstützt diesen Prozess auf vielfältige Weise. Ich habe insbesondere die Möglichkeit Themen einzufärben genutzt. Ebenso können Textmarker und Code-Favoriten den Prozess unterstützen. Eine weitere einfache Möglichkeit ist es Codes per Drag & Drop im Codesystem zu verschieben und so Ober-Codes zu erstellen, die es erlauben Unter-Codes zu gruppieren. Auf diese Weise habe ich Codefamilien erstellt, was mir bei der Definition und Benennung meiner Themen half.
Phase 6: Den Bericht erstellen
Auch wenn es erscheinen mag, als sei die letzte Phase der Textanalyse ein Happy End für mich gewesen, da ich die übergreifenden Themen und relevanten codierten Segmente identifiziert hatte, war sie in Wirklichkeit eine sehr schwierige Phase. Wie bei allen qualitativen Forschungsansätzen ist auch die Textanalyse ein rekursiver Prozess, und anders als bei der quantitativen Forschung gibt es hier keinen sequenziellen Prozess, bei dem die einzelnen Phasen erst dann eingeleitet werden, wenn die vorherige Phase abgeschlossen ist. Im Gegenteil, bei der Textanalyse musste ich sogar bis zur allerersten Phase der Datenanalyse zurückgehen, weil ich mich einfach wieder mit den Daten vertraut machen musste, um die übergreifenden Themen zu konstruieren.
Abbildung 6: Integration der Insights-Seite meines QTT-Arbeitsblatts
Schlussfolgerung
Durch den rekursiven Ansatz fühlte ich mich wirklich in meine Daten eingetaucht. Dies ist wichtig für die Berichterstattung über eine Textanalyse, denn ein Textanalyse-Bericht sollte eine „fesselnde Geschichte“ [für den Lesenden] über [meine] Daten auf der Grundlage [meiner] Analyse enthalten“ (Braun & Clarke, 2012, S. 69). Auf der letzten Seite meines QTT-Arbeitsblatts (siehe Abbildung 6) habe ich meine übergreifenden Themen und meine Forschungsfragen zusammengefasst und daraus Erkenntnisse gewonnen, Schlussfolgerungen gezogen und Hypothesen entwickelt. Außerdem habe ich die codierten Segmente auf der Registerkarte „Wichtige Segmente“ mit übergreifenden Themen verknüpft. Das QTT-Tool hat mir auch geholfen als es Zeit war meine Analyse und Ergebnisse niederzuschreiben.
Conclusion
Die qualitative Datenanalyse und insbesondere die Textanalyse mag wie eine entmutigende Aufgabe aussehen, bei der die Forschenden viel Zeit damit verbringen müssen, die Daten zu verstehen und daraus Hypothesen zu entwickeln. Im Gegensatz zu quantitativer Datenanalysesoftware, bei der ich mich aufgrund ihrer Point-and-Click-Oberfläche von meinen Daten losgelöst fühle, bietet qualitative Datenanalysesoftware Möglichkeiten, wirklich in den Datensatz einzutauchen, was für eine erfolgreiche (und sinnvolle) qualitative Forschung paradigmatisch entscheidend ist.
Abbildung 7: Der kontinuierliche Zyklus der Thematischen Analyse (in Anlehnung an Braun & Clarke, 2006, 2012)
Ein rekursiver Kreislauf der Bedeutungsfindung mit MAXQDA
Die Textanalyse ist ein Ansatz, der ein intensives Eintauchen in die Daten erfordert. Die vielen Funktionen von MAXQDA haben mir sehr geholfen, mich in die Daten zu vertiefen. Mit diesen Funktionen konnte ich mich wie „der Bildhauer“ (Braun & Clarke, 2012) fühlen, der auf dem Weg, etwas aus einem Steinblock zu erschaffen, Entscheidungen trifft. Dies ermöglichte es mir als Forscherin, bei der Datenanalyse eine eigene Stimme zu haben. Dieser Prozess hat die jüngste Diskussion um die Textanalyse angeregt, die den Sechs-Phasen-Ansatz als einen reflexiven Prozess neu konzeptualisiert (siehe Braun et al., 2019; Braun & Clarke, 2019, 2020). Mit MAXQDA konnte ich zwischen den Phasen der Textanalyse hin- und herspringen. Dank dieser Möglichkeit fühlte sich meine Textanalyse wie ein echter rekursiver Prozess an, wie in Abbildung 7 zu sehen ist, und nicht wie ein eher phasengesteuerter Prozess, bei dem nur die Phasen der Thematischen Analyse in linearer Reihenfolge aufgelistet werden, wie in Abbildung 1. Auf diese Weise konnte ich sehen, wie diese Phasen miteinander kommunizieren und einen kontinuierlichen und rekursiven Kreislauf der Bedeutungsgebung schaffen.
HINWEIS: Dieser Beitrag basiert auf meinen Forschungserfahrungen als Anwender von MAXQDA. Über das oben erwähnte Forschungsprojekt wurde bereits berichtet, und es befindet sich derzeit im Druck, um in der Juni-Ausgabe 2022 von The Journal of Teaching English with Technology veröffentlicht zu werden.
Braun, V., & Clarke, V. (2012). Thematic analysis. In H. Cooper (Ed.), APA handbook of research methods in psychology Vol 2: Research designs (Vol. 2, pp. 57–71). American Psychological Association. https://doi.org/10.1037/13620-004
Braun, V., & Clarke, V. (2019). Reflecting on reflexive thematic analysis. Qualitative Research in Sport, Exercise and Health, 11(4), 589–597. https://doi.org/10.1080/2159676X.2019.1628806
Braun, V., & Clarke, V. (2020). One size fits all? What counts as quality practice in (reflexive) thematic analysis? Qualitative Research in Psychology, 00(00), 1–25. https://doi.org/10.1080/14780887.2020.1769238
Braun, V., Clarke, V., Hayfield, N., & Terry, G. (2019). Thematic analysis. In P. Liamputtong (Ed.), Handbook of research methods in health social sciences (pp. 843–860). Springer. https://doi.org/10.1007/978-981-10-5251-4_103
Özgehan Uştuk, Ph.D. is a professional MAXQDA trainer and and currently works at Balikesir University, Turkey as a researcher, language teacher, and teacher educator. His research interests include language teacher education, practitioner inquiry, psychology of language teaching and learning, language teacher identity, emotions, and tensions. He is the incoming chair of the Research Professional Council in the TESOL International Association
Sie müssen den Inhalt von Turnstile laden, um das Formular abzuschicken. Bitte beachten Sie, dass dabei Daten mit Drittanbietern ausgetauscht werden.

Özgehan Uştuk, Ph.D. is a professional MAXQDA trainer and and currently works at Balikesir University, Turkey as a researcher, language teacher, and teacher educator. His research interests include language teacher education, practitioner inquiry, psychology of language teaching and learning, language teacher identity, emotions, and tensions. He is the incoming chair of the Research Professional Council in the TESOL International Association
 Özgehan Uştuk, Ph.D. is a professional MAXQDA trainer and and currently works at Balikesir University, Turkey as a researcher, language teacher, and teacher educator. His research interests include language teacher education, practitioner inquiry, psychology of language teaching and learning, language teacher identity, emotions, and tensions. He is the incoming chair of
Özgehan Uştuk, Ph.D. is a professional MAXQDA trainer and and currently works at Balikesir University, Turkey as a researcher, language teacher, and teacher educator. His research interests include language teacher education, practitioner inquiry, psychology of language teaching and learning, language teacher identity, emotions, and tensions. He is the incoming chair of